
Advanced analytics techniques like Machine Learning (ML) and Artificial Intelligence (AI) are becoming increasingly popular. However, ML model development has not yet reached the maturity of its cousin traditional Software Development.
Classic ML model development suffers four main downfalls
- Lack of governance and security
- Inconsistent development environment
- Poor change adaption and feedback cycles
- A large deployment gap
What is ML Ops?
Machine Learning Model Operationalisation Management (ML Ops) aims to provide a consistent, governed, and testable ML development process. An ML model is to ML Ops as application code is to DevOps.
So, does this mean that ML Ops is the same as DevOps?
Although ML Ops shares many similarities with DevOps, there are a few key distinctions. In this blog post we will highlight these differences, as well as some best practices to follow when rolling out ML Ops solutions.
Context
ML Ops is best suited to businesses who are looking to improve the quality and consistency of the models deployed, and who are seeking a clear path to production. Development for these businesses is largely ad hoc, with various teams working on different models.
We will work through my experiences providing platforms. There are many technologies out there to enable ML Ops, however for this post I will use Microsoft’s own horse in the race: Azure Machine Learning and Azure DevOps. To learn more about each of these services follow the links to the Microsoft documentation.
1. Governance and Security
Many operations people know that well-defined roles and responsibilities are key to functional and enforceable governance. Typically, we define the following roles:
- Platform Owner – administering ML Ops Azure resources, managing the Azure DevOps project, and creating/managing all pipelines, variable groups, service connections, etc.
- Platform Engineer – administering the ML Ops resources per each ML Ops Environment and the Continuous Deployment of models.
- Data Scientist – accessing data to develop and train machine learning models. Requires access to existing compute for model training but cannot create new compute.
Machine Learning can require large compute, and storage – these carefully defined roles mean that the relevant people in the business manage all infrastructure and subsequent costs.
Additionally, this allows data scientists to focus entirely on developing ML models, without worrying about spinning up compute.
Governance is enforced through Role-Based Access Control (RBAC) on Azure resources, and Teams in Azure DevOps.
Another crucial aspect of security is network isolation. Securing traffic behind a virtual network (vNet) means that only specified communications between devices or services are allowed. Azure Machine Learning is itself a PaaS service that can have private endpoint enabled, however it has dependencies on other resources such as Key Vault and blob storage. To secure all traffic, all these resources must be vNet enabled as well.

2. Development Consistency
ML model development is often interactive and ad hoc due to the experimental nature of data science. To enable experiments alongside production-ready software, we must introduce modularity in our project structure. An example of a good repository layout would be something like the following:

In this example, each directory serves a distinct purpose in the ML development lifecycle, logically separating initial experiments from production code.
This structure also provides the ability to create and run automated tests. Test-driven development is a cornerstone of traditional software development, ML Ops allows us to begin testing ML code units. For data scientist’s common unit tests could include:
- A model has been successfully trained
- The metrics are evaluated correctly
- A model scoring script outputs the expected schema
Structuring the project in this way promotes the git workflow, including developing models on feature branches, making pull requests, and peer reviews (almost expected in traditional software development) – guaranteeing code quality and collaboration.
3. Change adaption and feedback cycle
Unlike traditional software, machine learning requires the management of changes to the following artifacts:
- Data: The quality and schema of the data used to train the model
- Code: The code used to create the model
- Model: The model is a product of the data and the code and is the artifact that is ultimately deployed and consumed by end-users
A change in any of these would require refactoring or re-training of the model. The process of re-training an ML model can be considered at three levels of automation, outlined below.
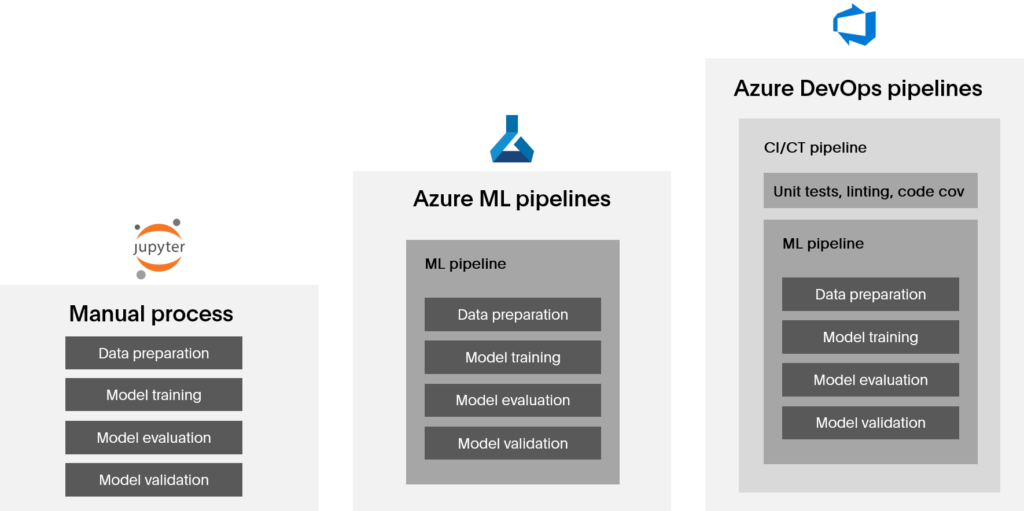
ML Ops focuses on enabling the third level of automation for production-ready models. Using Azure DevOps pipelines, we can run automated tests, linting, and code coverage (Continuous Integration) followed by triggering Azure ML pipelines to train, evaluate, and register models (Continuous Training). Once the training is complete, we tag the resulting models and Azure ML Experiments with the build id, training dataset id, and more.
Compared to the historically manual process of model training, integrating Azure DevOps builds in this way increases traceability and reproducibility. By automating the CI/CT process the ML model is kept up to date with the most recent changes.
4. Closing the Deployment Gap
Perhaps the biggest downfall to standard ML development is the lack of models that end up being deployed. A study on 750 executives, ML practitioners, and managers showed that for most companies, it takes between 31 to 90 days to deploy a model (See here for a more detailed breakdown of the original study).
At a high level, deploying an ML model involves packaging the inference dependencies (e.g., python or R packages) and serialised model (e.g., joblib or pickle file/files) into a docker container then uploading it into some compute.
It is often necessary to bridge the deployment gap through a variety of approaches.
Firstly, you need to ensure that the right deployment options are accessible to the relevant people. For example, a data scientist should be able to deploy their containerised model to a local environment to quickly test scoring, while model-specific continuous deployment (CD) pipelines in Azure DevOps should allow a platform engineer to push models quickly and easily to production.
On production deployment, my colleagues and I have typically had great success utilising a container ochestrator like Azure Kubernetes Service (AKS) to orchestrate and scale multiple model containers with multi-node compute. This can be infrastructure shared across multiple teams to save cost.
Lastly, and crucially, you must place approval gates on all Azure DevOps deployment pipelines, ensuring the governance model is enforced. No ML model should ever be pushed into production without approval.
Conclusion
ML Ops is the foundation for ML model development, much like DevOps for traditional software development.
An integrated ML Ops solution provides the next step in the evolution of modern data and analytics and helps enable the primary end-goal of Machine Learning – serving the predictive power of ML to end-users.